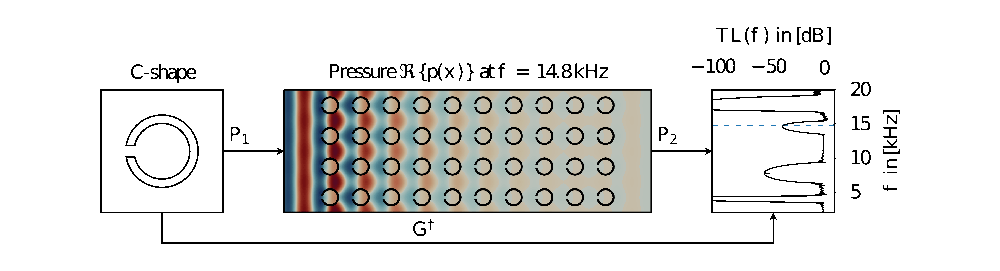
Neural Operators as Fast Surrogate Models for the Transmission Loss of Parameterized Sonic Crystals, NeurIPS 2024, D3S3 Workshop
This collaboration of the Chair of Vibroacoustics of Vehicles and Machines at TUM with my team is part of our investigation of the use of deep learning to accelerate physical simulations.
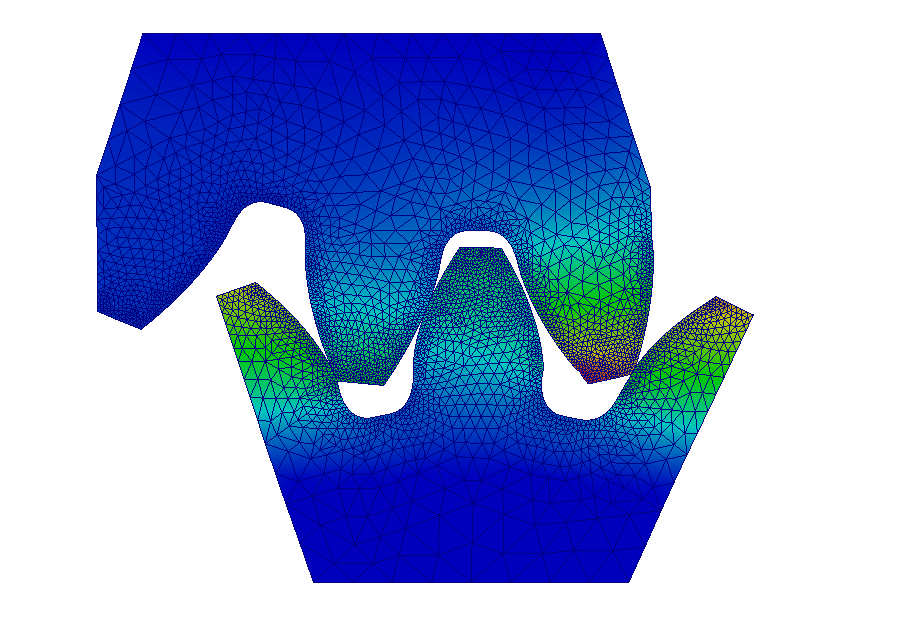
Neural operators serve as efficient, data-driven surrogate models for complex physical and engineering problems. In this work, we demonstrate that neural operators can directly learn the key properties of sonic crystals, a type of acoustic metamaterial consisting of a lattice of parameterized shapes. We predict the transmission loss curve, a critical characteristic in applications, bypassing the expensive meshing and solving steps typical of classical techniques. We evaluate established architectures (DeepONet, FNO) alongside two new ones (DNO, DCO), which demonstrate significant performance improvements. In our experiments, all models achieve high accuracy, while being up to 10⁶ times faster than traditional methods, significantly advancing practical real-time metamaterial design.
All experiments were run by Jakob Elias Wagner, with the support of Johannes D. Schmid, and Samuel Burbulla, the lead developer of continuiti, our library for neural operator learning used for the experiments. The paper was accepted in the NeurIPS 2024 Workshop on Data-driven and Differentiable Simulations, Surrogates, and Solvers.